If only CRO was so easy: find the exact point at which the user loses interest in a page. Figure out why. Fix it. Eat a bagel.
If you’re reading this, it’s likely that you’re familiar with the obstacles that prevent this dream from fruition.
For over a decade we have worked hard to figure out ways to simplify this. CRO is never that easy. But identifying problems and figuring out why can be easier than one thinks.
The Scrutinize in the SHIP Methodology
Since the very moment we founded Invesp, we’ve worked on optimizing our approach to figure out the what, the why and how to optimization. Working with some of the top companies in the world like 3M, Ericsson and The Discovery Channel, and eBay, helped us continuously improve our processes. And until this day, we are working diligently on optimizing our process for greater results.

The What
One of the first questions and obstacles we face is the what. What is the problem? This can be discovered through some qualitative and quantitative analysis, one method that we will be delving in deeper in this article. But the way you gather “the what” is one of the most critical parts of conversion rate optimization.
The Why
If you’ve done your qualitative collecting correctly, then you will be able to figure out the why something is a problem with visitors. Quantitative data on the other hand is used one of two ways: to justify qualitative data collected, or to offer more problems and investigate further.
The How
Once you’ve collected the problems, identified why it’s occurring, and now it’s important to decide how I will solve it. This is where the hypothesis becomes critical. Your hypothesis must answer “the why” in problem identification.
This methodology of asking these questions and using the tools to answer them paved the way to develop a unique 12-step conversion framework to maintain incremental improvements and a solid, data-backed process called the SHIP method. Ship stands for: scrutinize, hypothesize, implement, propagate. Most of the work (the research) falls with the scrutinize phase.
The optimization cycle begins with analysis of an existing design. The analysis of a website from the perspective of conversion optimization covers two aspects : behavioral and analytical (assessed by metrics such as user count, bounce rate, engagement time) and attitudinal or qualitative (obtained from user feedback through surveys, feedback forms among other methods).
Now traditional quantitative metrics have their place in the analysis process but they don’t answer the why behind a particular number.
Instead of looking at indirect indicators of user experience that map computer performance, we need a simple, elegant way to measure the quality of human-computer interaction for a page.
That’s where PURE comes in. Note, this method is one of the 4 or 5 different expert review methodologies Invesp deploys during the scrutiny phase. It is not an end all method to figuring out problems, but one tool amongst many to help put a robust roadmap together.
PURE Method- And experts insight into usability

A relatively new, simple method of analyzing user behavior: Pragmatic Usability Rating by Experts is separate from the quantitative or qualitative data metrics. This new method involves rating the design of every basic action on a page by an experienced expert user. Christian Rohrer explains:
“One big difference from heuristic evaluation is that, in PURE, the panel sees the same experience together, which ensures that they rate the same thing — otherwise their scores would be wildly different. This point highlights an important difference in goals between heuristic evaluation and PURE.”
Basics of PURE usage
PURE is a lot like Uber’s driver rating system. Uber allows you to rate every driver based on the experience that you have with them, ranging from 1 star to 5 stars. The driver then gets an overall rating – the average of all the user ratings they have received over their Uber career. It represents the overall user experience that a driver provides. This rating determines which driver gets more lucrative rides.
The main difference is that unlike Uber’s rating system which allows any user to submit a rating, PURE employs experienced experts who are knowledgeable about user experience. These experts also have a very accurate idea of the target user and can be expected to have much less bias than the average person. This provides a reliable way to gauge user experience that is also low in cost.
What is PURE?

Definition : PURE is a usability-evaluation method in which usability experts assign one or more quantitative ratings to a design based on a set of criteria and then combine all these ratings into a final score and easy-to-understand visual representation.
PURE judges design based on only one factor : Ease of use.
This is a result-oriented approach. If the ease of using a particular element on the page is low, the user may lose interest at this point. Consequently, he doesn’t get to utilize the remaining elements and features on a page. This metric is hence critical towards allowing users to proceed with a certain flow.
What does PURE do?
PURE gives a very good idea of pain points from the user’s point of view. This allows designers and developers to review and fix the same. The improved implementation may be rated again to ascertain the degree of improvement.
Employed over iterations, PURE acts as a reliable method to improve the ease of use of every element in a design.
Is PURE valid and reliable?
When comparing PURE results with metrics obtained from running a usability-benchmarking study on the same product, we found statistically significant correlations with SEQ and SUS (popular ease-of-use survey measures) of 0.5 (p <0.05) and 0.4 (p < 0.01), respectively. These numbers reflect that PURE has at least reasonable validity, when compared with standard quantitative metrics, at statistically significant levels (p< 0.05). Interrater reliability calculations for PURE have ranged from 0.5 to 0.9, and are generally very high (above 0.8) after expert raters are trained on the method. Jeff Sauro explains:
“Most UX methods—such as usability testing, card sorting, and surveys are empirical, the PURE method is analytic. It’s not based on directly observing users, but instead relies on experts making judgments on the difficulty of steps users would take to complete tasks. It’s based on principles derived from user behavior.”
In a recent PURE evaluation at Capital One, three experts achieved an interrater reliability score of 1.0 (100% agreement) across 9 fundamental tasks. As of this writing, PURE is known to have been used with over 15 different products at 3 companies.
How to carry out a PURE analysis

Applying the PURE method to a product or service is a stepwise process with 8 necessary and 2 optional steps.
- Identifying target group of users.
- Select the fundamental tasks of this product for target users.
- State the path of least resistance for each fundamental task.
- Determine step boundaries for each task and label them in a PURE score sheet.
- Collect PURE scores from three expert raters who walk through the desired paths of the fundamental tasks together and silently rate each step.
- Calculate the inter-rater reliability for the raters’ independent scores to ensure disagreement among experts doesn’t ensue.
- Have the expert panel discuss ratings and rationale for individual scores, and then agree on a single score for each step.
- Sum the PURE scores for each fundamental task and for the entire product; color each step, task, and product appropriately.
Step 1: Target User Types
To make continuous and consecutive estimations regarding ease of use, PURE experts must have a well-defined user type. Specific user qualities are given more weight and influence the experts’ evaluations.
The decision and any assumptions about the target user’s context must be documented for future scoring purposes. Target user types based on personas work well as it functions similar to a heuristic. However, a well-defined user description can work in practice as well, as long as behaviors and rationale for those behaviors can be understood by the expert panel. A clear target user type will help the PURE raters be consistent in their ratings.

It is possible to identify and score against multiple target user types, however, it drastically increases the worked entailed for scoring. In practice, target user types should be limited to no more than 2–3 in order to maintain its pragmatic functioning.
Step 2: Fundamental Tasks
Fundamental tasks are tasks that either:
- Are critical for the business to succeed (e.g., payment/checkout), or
- Allow target users to meet their core needs (assuming the product or service offers a value proposition that meets some of those needs).
Websites or software easily consists of more than 20 tasks. However, most mobile applications pertain to a flexible range of 8-15 fundamental tasks. Hence, a suitable limit should exist on the number of fundamental tasks that a product can have in order to reach an optimal result.
Step 3: Desired Paths
When utilizing assessment methods such as cyclomatic complexity of a software, multiple task-node accessing sequences can be created. However, there exist only a few ideal paths in order to test out all the possible fundamental tasks. PURE evaluation requires the use of such desired paths.
While it would be prudent to consider evaluating all paths, it would not be necessary since the performance of the product is node dependent. Other methods, like heuristic evaluation or standard usability studies, would be sufficient to find and fix problems in other paths and hence alternative path approach for PURE evaluation should be ignored.
Step 4: Step Boundaries
Once the desired paths are determined, it is crucial to investigate where each step begins and ends. Depending on the type of interaction provided by the product or service, this process can be harder than imagined. The place to start is the “default step” definition:
- A step can be considered a beginning if it provides the user with a set of options.
- A step can be demarcated as terminal, if the user has taken an action, and is expecting a plausible system response to that action.
- Micro-interactions are treated as in-between steps.
One point to be noted is, that, when a user is waiting for a system response, there might be many processes that take place in an area that is abstracted from the user. Hence, while evaluating the PURE score, a decision should be made whether to inculcate or ignore these hidden processes.
Step 5: Review by Three Expert Raters

The natural approach makes use of three usability professionals (ideally UX researchers) to provide the initial pure ratings. The panel assembles and all members watch as the lead researcher goes through each project on a common display and declares when each step begins and ends. Each panel member silently rates and reviews each step, making notes about the rationale for the rating. The notes can include observed usability problems, as in heuristic evaluations.
PURE aims to provide a reliable measure of how easy it is for the most important user type to accomplish only the fundamental tasks, through the best design offered at this point. The analysis starts here because these are most important areas to get right. Once improved, the PURE method can be used elsewhere, although it may not be necessary to provide a numerical score for all paths, tasks, and user types.
Step 6: Inter-rater Reliability Calculations
To see how much the experts agreed with each other in their individual PURE scores, which were provided silently, you should calculate the “inter-rater reliability” (IRR).
IRR measures a coefficient of agreement between raters, based on their comprehension of the targeted user. Their results are expressed in a range of 1-3 rubric. A coinciding value helps experts to understand whether they made concurrent assumptions while scoring their products in PURE
IRR ranges from -1 to 1, but is typically between 0.5 and 1.0.If a threshold of 0.667 isn’t acquired, discussions between the experts should be carried out and they should simply consider this PURE evaluation to be a training session. A few rounds are often required to ensure that all are on the same figurative boat.
Step 7: The Decided PURE Score
Once individual recording between experts has been accounted for, they should indulge in a conversation which discusses the task details and understandings. This discussion is invaluable for two main reasons:
- Gaining insight from colleagues and improving the evaluation judgment.
- The expert panel will be able to reach a conclusive rating and then, record it into the PURE evaluation scoring
Mostly, the score variance between the raters is relatively low, however, the evaluation may be prone to human error arising from lack of clarity of evaluation.
Of course, coincidences will occur, in which the three raters have rated the product task with different scores. This occurs due to a difference in insights and interpretations over a step sequence.The assumptions decided upon should be documented for future review and PURE scoring. Average scoring is avoided since the scoring should display the generalized opinion, and not the average notion of all experts.
Step 8: Summing It Up into Green, Yellow, and Red
This step consists of summing up the decided PURE step scores into the task PURE scores, and then summing the task PURE scores into the product PURE score. This task often requires normalization of all the scores, and at times might curtail certain fundamental steps that have been evaluated.

Bar graphs and tri-color schema is utilized for easier readability:
Green: The best case possible, this zone is where all the tasks aspire to be in. However, just because a task is in the green zone doesn’t mean that it can’t be improved upon.
Yellow: This rating is considered acceptable, however, it has plenty of scope for improvement.
Red: Usually considered as the zone with the highest friction. Solving these will have a massive impact on the score rating. These tasks should be considered top priority when going for performance tweaking.
Friction and How it’s measured
PURE doesn’t deal with factors affecting user experience apart from ease of use. The effectiveness for quantifying usability is retained as the user persona is framed.
Using data points that do not reflect the current appeasement level of the user may is prone to showing false causative relationships which are to be avoided. In the PURE method, in keeping with the ultimate objective of retention through user appeasement, quantifying the ease of use with numbers that represent how difficult a particular action is for the user presents the ideal solution.
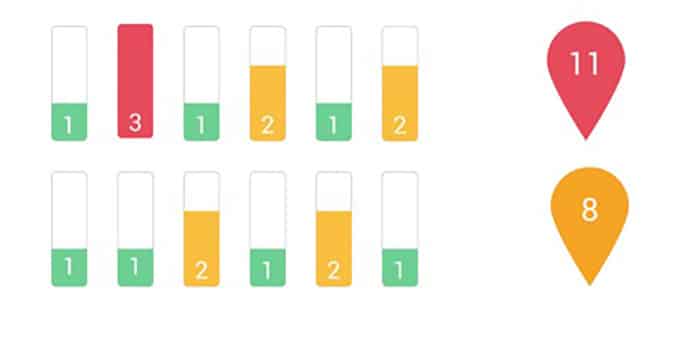

A rating of 2: means the cognitive load of the action is moderate. It is not the simplest to carry out but is also not highly draining. These actions are marked by the color yellow.
A rating of 3: means the cognitive load of the action is high. This is undesirable. The user is likely to lose interest while executing the action. These actions are marked by the color red.
Once every action is rated by an expert, a clear picture of the pain points is obtained.
These are to be worked upon in the next step, which is optimization.
Observations on PURE for optimal use
“The PURE method is not a replacement for usability testing. In our experience, it’s ideally used for identifying low-hanging problems in an interface that’s unlikely to be tested with users (because of cost, priority, or difficulty testing it) and when a metric about the experience is needed for management.”
Remember when conducting Pure: The PURE method, is more qualitative centric, and hence should be utilized primarily for qualitative analysis of UX. Since people value metrics highly when evaluating results, PURE gives them exactly that, making it developer friendly. And finally, a higher number of experts can be deployed for the task, the tradeoff being between IRR and precision.